[파이썬 머신러닝 완벽가이드(위키북스)] : 텍스트 분석 part7 한글 텍스트 처리 - 네이버 영화 평점 감성 분석
이번에는 네이버 영화 평점 데이터를 기반으로 감성 분석을 적용해 보았다. 네이버 영화 평점 데이터는 파이썬 머신러닝 완벽가이드(위키북스)의 깃허브에서 다운을 받았다. 데이터셋을 다운을 받은 후 파일의 형태가 어떻게 되어있는지 알아보았다.
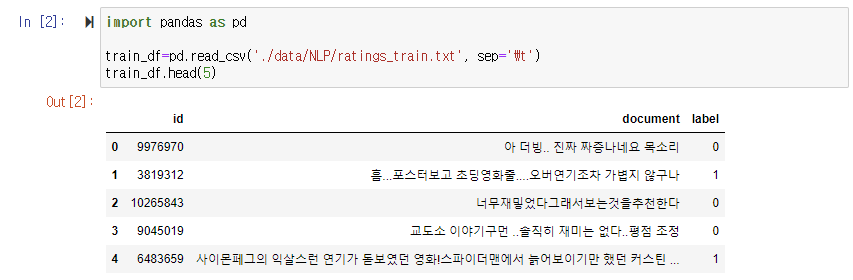
열을 구분하기위한 id와 사람들이 평점에 남긴 말인 document 그리고 해당 리뷰가 긍정인지 부정인지 나타내는 label 값이 있다. 1이 긍정 0이 부정 감성이다. 두 비율은 거의 50대 50인 것으로 보인다. 마지막으로 리뷰가 Null 값인 열은 5개이다.
Null이 일부 존재하는 것을 알 수 있다. 이는 사실 제거를 해주어도 되는 수준이기는 하지만 일단 파이썬의 정규 표현식 모튤인 re를 이용해 이 역시 아예 공백으로 변환을 한다.

이제 TF-IDF 방식으로 단어를 벡터화할 텐데, 먼저 각 문장을 한글 형태소 분석을 통해 형태소 단어로 토큰화를 해야한다. 한글 형태소 엔진은 SNS 분석에 적합한 Twitter 클래스를 이용한다. Twitter 객체의 morphs() 매서드를 이용하면 입력 인자로 들어온 문장을 형태소 단어 형태로 토큰화해 list 객체로 반환한다. 문장을 형태소 단어 형태로 반환하는 별도의 함수 tw_tokenizer()를 만들었다. 해당 함수를 사용해서 사이킷런의 TfidfVectorizer를 이용해 변환을 시켜준다. 그 이후 로지스틱 회귀를 이용해 분류 기반의 감성 분석을 수행한다.
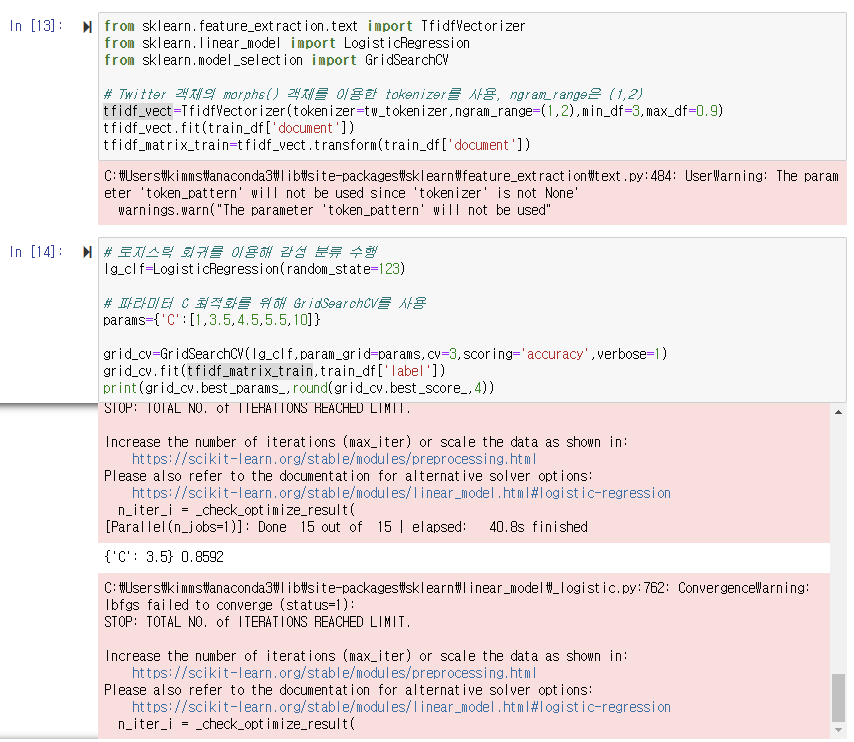
C가 3.5일 때 최고 점수의 정확도를 보였다.
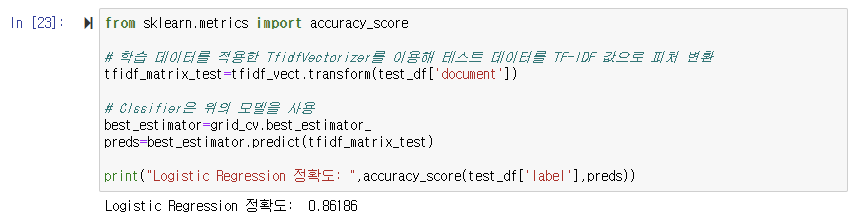
테스트 데이터를 이용해 test score를 측정할 때는 학습할 때 적용한 TfidfVectorizer를 그대로 사용을 해야한다. 그래야만 학습 시에 설정된 TfidfVectorizer의 피처 개수와 테스트 데이터를 TfidfVectorizer로 변환한 피처 개수가 같아진다.
텍스트 분석 part 정리
이번 part에서는 텍스트 분석을 위한 기반 프로세스를 상세히 알아보고, 이를 통해 텍스트 분류, 감성 분석, 토픽 모델링, 텍스트 군집화 및 유사도 측정 등을 직접 파이썬 코드를 이용해 구현을 해 보았다. 머신러닝 기반의 텍스트 분석 프로세스는 첫째 텍스트 사전 정제 작업 등의 텍스트 정규화 작업을 수행하고 둘째 이들 단어들을 피처 벡터화로 변환한다. 셋째, 이렇게 생성된 피처 벡터 데이터 세트에 머신러닝 모델을 학습하고 예측, 평가한다.
텍스트 정규화 작업은 텍스트 클렌징 및 대소문자 변경, 단어 토큰화, 의미 없는 단어 필터링, 어근 추출 등 피처 벡터화를 진행하기 이전에 수행하는 다양한 사전 작업을 의미한다. 피처 벡터화는 BOW의 대표 방식인 Count 기반과 TF-IDF 기반 피처 벡터화가 있었다. 일반적으로 문서의 문장이 긴 경우에는 TF-IDF 기반의 피처 벡터가 더 정확한 결과를 도출하는 데 도움이 된다. 이렇게 만들어진 피처 벡터 데이터 세트는 희소 행렬이며, 머신러닝 모델은 이러한 희소 행렬 기반에서 최적화되어야 한다.