[파이썬 머신러닝 완벽가이드(위키북스)] : Clustering (군집화) Part2
평균 이동(Mean Shift)의 개요
평균 이동은 K-평균과 유사하게 중심을 군집의 중심으로 지속적으로 움직이면서 군집화를 수행한다. 하지만 K-평균이 중심에 소속된 데이터의 평균 거리 중심으로 이동하는데 반해, 평균 이동은 중심을 데이터가 모여 있는 밀도가 가장 높은 곳으로 이동시킨다.
평균 이동 군집화는 데이터의 분포도를 이용해 군집 중심점을 찾는다. 군집 중심점은 데이터 포인트가 모여있는 곳이라는 생각에서 착안한 것이며 이를 위해 확률 밀도 함수를 이용한다. 가장 집중적으로 데이터가 모여 있어 확률 밀도 함수가 피크인 점을 군집 중심점으로 선정하며 일반적으로 주어진 모델의 확률 밀도 함수를 찾기 위해서 KDE(Kernel Density Estimation)를 이용한다.
평균 이동 군집화는 특정 데이터를 반경 내의 데이터 분포 확률 밀도가 가장 높은 곳으로 이동하기 위해 주변 데이터와의 거리 값을 KDE 함수 값으로 입력한 뒤 그 반환 값을 현재 위치에서 업데이트하면서 이동하는 방식을 취한다. 이러한 방식을 전체 데이터에 반복적으로 적용하면서 데이터의 군집 중심점을 찾아낸다.
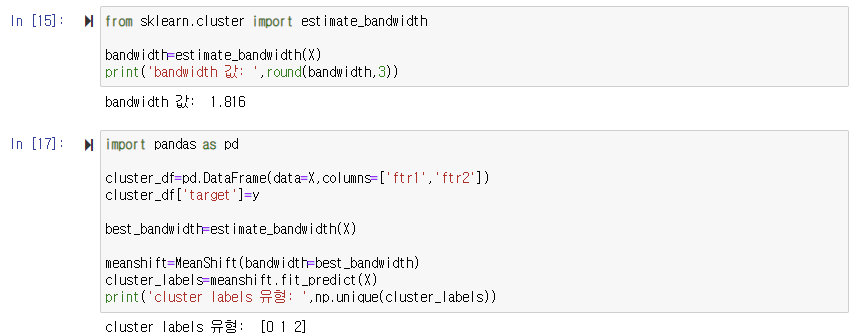
사이킷런은사이킷런은 평균 이동 군집화를 위해 MeanShift 클래스를 제공한다. MeanShift 클래스의 가장 중요한 초기화 파라미터는 bandwidth이며 이 파라미터는 KDE의 대역폭 h와 동일하다. 대역폭 크기 설정이 군집화의 품질에 큰 영향을 미치기 때문에 사이킷런은 최적의 대역폭 계산을 위해 estimate_bandwidth() 함수를 제공한다. 다음 예제는 make_blobs()의 cluster_std를 0.7로 정한 3개의 군집 데이터에 대해 bandwidth를 0.8로 설정한 평균 이동 군집화 알고리즘을 적용한 예제이다.

군집이 0부터 5까지 6개로 분류됐다. 지나치게 세분화된 군집화이다. 일반적으로 bandwidth값을 작게 할수록 군집 개숙 많아진다. 이번에는 bandwidth를 살짝 높인 1.0으로 해서 MeanShift를 수행해보았다.

데이터의 분포 유형에 따라 bandwidth 값의 변화는 군집화 개수에 큰 영향을 미칠 수 있다. 따라서 MeanShift에서는 이 bandwidth를 최적화 값으로 설정하는 것이 매우 중요하다. 사이킷런은 최적화된 bandwidth 값을 찾기 위해 estimate_bandwidth() 함수를 제공한다. estimate_bandwidth()의 파라미터로 피처 데이터 세트를 입력해주면 최적화된 bandwidth 값을 반환해준다.


평균 이동의 장점은 데이터 세트의 형태를 특정 형태로 가정한다든가, 특정 분포도 기반의 모델로 가정하지 않기 때문에 좀 더 유연한 군집화가 가능한 것이다. 또한 이상치의 영향력도 크지 않으며, 미리 군집의 개수를 정할 필요도 없다. 하지만 알고리즘의 수행 시간이 오래 걸리고 무엇보다도 band-width의 크기에 따른 군집화 영향도가 매우 크다.
이 같은 특징 때문에 일반적으로 평균 이동 군집화 기법은 분석 업무 기반의 데이터 세트보다는 컴퓨터 비전 영역에서 더 많이 사용된다. 이미지나 영상 데이터에서 특정 개체를 구분하거나 움직임을 추적하는 데 뛰어난 역할을 수행하는 알고리즘이다.
GMM(Gaussian Moxture Model)
GMM 군집화는 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정하에 군집화를 수행하는 방식이다. 정규 분포로도 알려진 가우시안 분포는 좌우 대칭형의 종 형태를 가진 통계학에서 가장 잘 알려진 연속 확률 함수이다. GMM은 데이터를 여러 개의 가우시안 분포가 섞인 것으로 간주한다. 섞인 데이터 분포에서 개별 유형의 가우시안 분포를 추출한다. GMM은 확률 기반 군집화이고 K-평균은 거리 기반 군집화이다. 이번에는 붓꽃 데이터 세트로 이 두 가지 방식을 이용해 군집화를 수행한뒤 양쪽 방식을 비교해 보았다.

GaussianMixture 객체의 가장 중요한 초기화 파라미터는 n_components이다. n_components는 gaussian mixture의 모델의 총개수이다. K-평균의 n_clusters와 같이 군집의 개수를 정하는데 중요한 역할을 수행한다. n_componenets를 3으로 설정하고 GaussianMixture로 군집화를 수행. GaussianMixture 객체의 fit와 predict를 수행해 군집을 결정한 뒤 iris_df DataFrame에 'gmm_cluster'칼럼 명으로 저장하고 나서 타깃별로 군집이 어떻게 매핑됐는지 확인해 보았다.
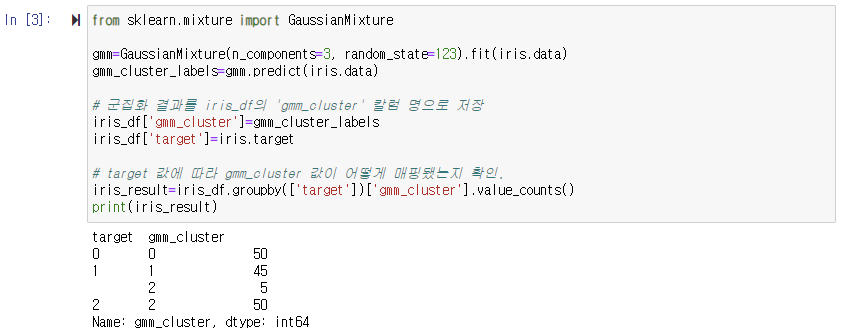

k-means보다 gmm이 성능이 나은 것을 알 수 있다. 하지만 모든 데이터의 경우에서 gmm이 성능이 항상 성능이 좋은 것은 아니다. k-means는 평균 거리 중심으로 중심을 이동하면서 군집화를 수행하는 방식이므로 개별 군집 내의 데이터가 원형으로 흩어져 있는 경우 매우 효과적으로 군집화가 수행될 수 있다.
GMM과 K-평균의 비교
K-Means는 원형의 범위에서 군집화를 수행한다. 데이터 세트가 원형의 범위를 가질수록 K-Means의 군집화 효율은 더욱 높아진다. 아래는 군집의 수를 3개로 하면서 군집 내의 데이터를 긴 타원형으로 ㄴ뭉치게 유도한 데이터 세트이다. 이 데이터 세트에 대해서 군집화를 수행하였을 때 K-Means와 GMM과의 차이를 알아보았다.

K-Means로 군집화
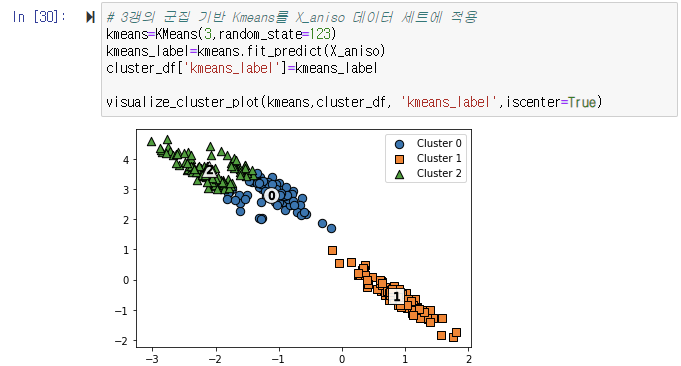
K-Means로 군집화를 수행할 경우, 주로 원형 영역 위치로 개별 군집화가 되면서 원하는 방향으로 구성되지 않음을 알 수 있다. K-Means가 평균 거리 기반으로 군집화를 수행하므로 같은 거리상 원형으로 군집을 구성하면서 위와 같이 길쭉한 방형으로 데이터가 밀접해 있을 경우에는 군집화가 어렵다.
GMM으로 군집화
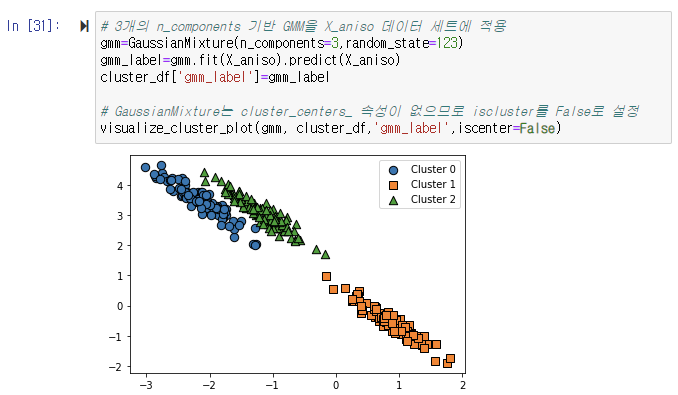
데이터가 분포된 뱅향에 따라 정확하게 군집화됐음을 알 수 있다. GMM은 K-Means와 다르게 군집의 중심 좌표를 구할 수 없기 때문에 군집 중심 표현이 visualize_cluster_plot()에서 시각화되지 않는다. 위에서 만든 데이터 세트의 target값과 KMean, GMM의 군집 Label 값을 서로 비교해 위와 같은 데이터 세트에서 얼마만큼의 군집화 효율 차이가 발생하는지 확인해보자.

K-Means의 경우 군집 1번만 정확하게 mapping 하였고 나머지 군집의 경우 target값과 어긋나는 경우가 발생했다. 하지만 GMM의 경우는 군집이 target 값과 잘 매핑된 것을 알 수 있다.
GMM의 경우는 K-Means보다 유연하게 다양한 데이터 세트에 잘 적용될 수 있다는 장점이 있다. 하지만 군집화 수행을 위한 시간이 오래 걸린다는 단점이 있다.
DBSCAN
밀도 기반 군집화의 대표적인 알고리즘이다. DBSCAN은 간단하고 직관적인 알고리즘으로 돼있음에도 데이터의 분포가 기하학적으로 복잡한 데이터 세트에도 효과적인 군집화가 가능하다. 아래와 같이 내부의 원 모양 형태의 분포를 가진 데이터 세트를 군집화한다고 가정할 때 앞서 말한 K-Means, 평균 이동, GMM으로는 효과적인 군집화를 수행하기가 어렵다. DBSCAN은 특정 공간 내에 데이터 밀도 차이를 기반 알고리즘으로 하고 있어서 복잡한 기하학적 분포도를 가진 데이터 세트에 대해서도 군집화를 잘 수행한다.

DBSCAN을 구성하는 가장 중요한 두 가지 파라미터는 입실론(epsilon)으로 표기하는 주변 영역과 입실론 주변 영역에 포함되는 최소 데이터의 개수 min points이다.
입실론 주변 영역(epsilon): 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
최소 데이터 개수(min points): 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 개수
입실론 주변 영역 내에 포함되는 최소 데이터 개수를 충족시키는가 아닌가에 따라 데이터 포인트를 다음과 같이 정의한다.
핵심 포인트(Core point): 주변 영역 내에 최소 데이터 개수 이상의 타 데이터를 가지고 있을 경우 해당 데이터를 핵심 포인트라고 한다.
이웃 포인트(Neighbor point): 주변 영역 내에 위치한 타 데이터를 이웃 포인트라고 한다.
경계 포인트(Border point): 주변 영역 내에 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않지만 핵심 포인트를 이웃 포인트로 가지고 있는 데이터를 경계 포인트라고 한다.
잡음 포인트(Noise point): 최소 데이터 개수 이상의 이웃 포인트를 가지고 있지 않으며, 핵심 포인트도 이웃 포인트로 가지고 있지 않는 데이터를 잡음 포인트라고 한다.
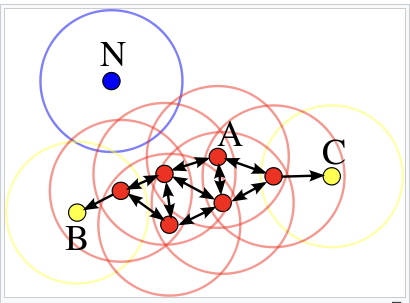
위 그림을 통해 설명 하면 A는 자신의 반경(입실론) 안에 포함된 데이터가 3개이므로 최소 데이터 수를 만족함으로 핵심 포인트이다 그렇게 빨간색 점들은 모두 핵심 포인트이자 서로의 이웃 포인트인 것이다. 이렇게 이웃 포인트를 확장하는 방식으로 군집을 형성한다. C와 B는 입실론에 포함된 데이터 수가 최소 데이터 수를 만족하지 못하지만 빨간색 점(핵심 포인트)과는 범위에 들기 때문에 경계 포인트가 된다. 이렇게 경계 포인트가 형성되면서 군집의 외각이 형성된다. N은 입실론 범위 안에 드는 점들이 하나도 없기 때문에 잡음 포인트가 된다.
DBSCAN은 이처럼 입실론 주변 영역의 최소 데이터 개수를 포함하는 밀도 기준을 충족시키는 데이터인 핵심 포인트를 연결하면서 군집화를 구성하는 방식이다. 사이킷런은 DBSCAN 클래스를 통해 DBSCAN 알고리즘을 지원한다. DBSCAN 클래스는 다음과 같은 주요한 초기화 파라미터를 가지고 있다.
eps: 입실론 주변 영역의 반경을 의미한다.
min_samples: 핵심 포인트가 되기 위해 입실론 주변 영역 내에 포함돼야 할 데이터의 최소 개수를 의미한다.(여기서 자신의 데이터를 포함한다.)
DBSCAN 적용하기
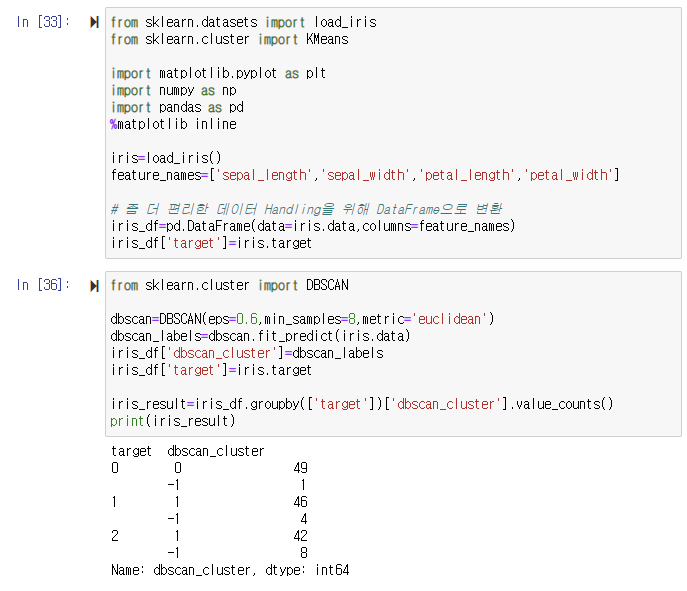
결과 창을 보면 알 수 있는데 0과 1이외에 특이하게 -1이 군집 레이블로 있는 것을 알 수 있다. 군집 레이블이 -1인 것은 노이즈에 속하는 군집을 의미한다. 따라서 위 붓꽃 데이터 세트는 DBSCAN에서 0과 1 두 개의 군집으로 군집화됐다. Target 값의 유형이 3가지인데, 군집이 2개가 됐다고 군집화 효율이 떨어진다는 의미는 아니다. DBSCAN은 군집의 개수를 알고리즘에 따라 자동으로 지정하므로 DBSCAN에서 군집의 개수를 지정하는 것은 무의미하다고 할 수 있다.
DBSCAN으로 군집화 데이터 세트를 2차원 평면에서 표현하기 위해 PCA를 이용해 2개의 피처로 압축 변환한 뒤, 앞 예제에서 사용한 visualize_cluster_plot() 함수를 사용해 시각화해보자.
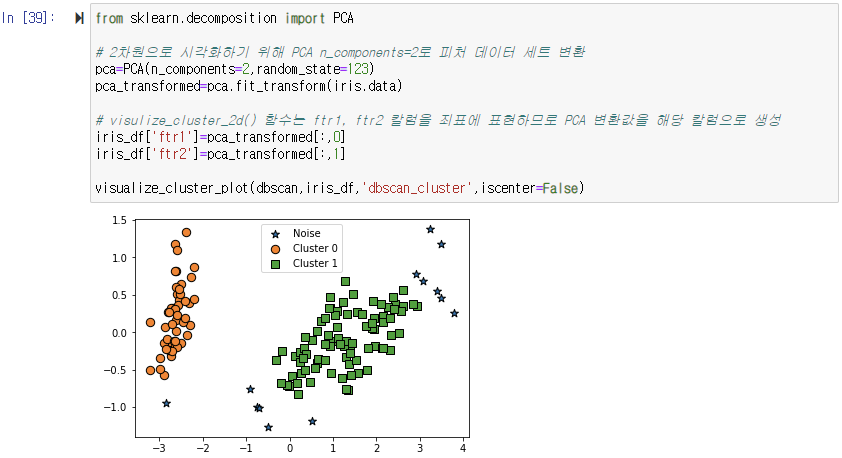
DBSCAN을 적용할 때는 특정 군집 개수로 군집을 강제하지 않는 것이 좋다. DBSCAN 알고리즘에 적절한 eps와 min_samples 파라미터를 통해 최적의 군집을 찾는 게 중요하다. 일반적으로 eps의 값을 크게 하면 반경이 커져 포함하는 데이터가 많아지므로 노이즈 데이터 개수가 작아진다. min_samples를 크게 하면 주어진 반경 내에서 더 많은 데이터를 포함시켜야 하므로 노이즈 데이터 개수가 커지게 된다. 데이터 밀도가 더 커져야 하는데, 매우 촘촘한 데이터 분포가 아닌 경우 노이즈로 인식하기 때문이다.

노이즈 군집인 -1이 3개 뿐이다. 이번에는 eps는 유지하고 min_samples를 16으로 늘려보자.

노이즈 데이터가 기존보다 많이 증가함을 알 수 있다.
정리
각 군집화 기법은 나름의 장/단점을 가지고 있으며, 군집화하려는 데이터의 특성에 맞게 선택해야 한다.
K-Means의 경우 거리 기반으로 군집 중심점을 이동시키면서 군집화를 수행한다. 매우 쉽고 직관적인 알고리즘으로 많은 군집화 애플리케이션에서 애용되지만, 복잡한 구조를 가지는 데이터 세트에 적용하기에는 한계가 있으며, 군집의 개수를 최적화하기가 어렵다. K-Means은 군집이 잘 되었는지 평가를 위해 실루엣 계수를 이용한다.
Mean-Shift(평균 이동)은 K-Means와 유사하지만 거리 중심이 아니라 데이터가 모여 있는 밀도가 가장 높은 쪽으로 군집 중심점을 이동하면서 군집화를 수행한다. 일반 업무 기반의 정형 데이터 세트보다는 컴퓨터 비전 영역에서 이미지나 영상 데이터에서 특정 개체를 구분하거나 움직임을 추적하는 데 뛰어난 역할을 수행하는 알고리즘이다.
GMM 군집화는 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포를 모델을 섞어서 생성된 모델로 가정해 수행하는 방식이다. 전체 데이터 세트에서 서로 다른 정균 분포 형태를 추출해 이렇게 다른 정규 분포를 가진 데이터 세트를 각각 군집화하는 것이다. GMM의 경우는 K-Means보다 유연하게 다양한 데이터 세트에 잘 적용될 수 있다는 장점과 군집화를 위 한 수행 시간이 오래 걸린다는 단점이 있다.
DBSCAN은 밀도 기반 군집화의 대표적인 알고리즘이다. DBSCAN은 입실론 주변 영역 내에 포함되는 최소 데이터 개수의 충족 여부에 따라 데이터 포인트를 핵심 포인트, 이웃 포인트, 경계 포인트, 잡음 포인트로 구분하고 특정 핵심 포인트에서 직접 접근이 가능한 다른 핵심 포인트를 서로 연결하면서 군집화를 구성하는 방식이다. DBSCAN은 간단하고 직관적인 알고리즘으로 돼 잇음에도 데이터의 분포가 기하학적으로 복잡한 데이터 세트에도 효과적인 군집화가 가능하다.