사이킷런
파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리이다.
튜토리얼로 가장 많이 사용되는 붓꽃 품종 예측하기
일단 사이킷런 데이터를 불러오고 데이터 프레임을 보면

label 이 품종 이름이 아닌 숫자로 되어 있다. 이를 좀 더 직관적으로 이름으로 mapping하고 싶다면 앞서서 배운 lambda 함수를 사용을 하거나 혹은 아래와 같이 map기능을 사용하면 된다.

train_test_split
머신러닝을 진행 할 때 학습용 데이터셋과 테스트용 데이셋은 반드시 분리를 해야한다. 이때 하나하나 indexing 직접하는 것이 아닌 train_test_split을 활용해서 내가 원하는 비율 그리고 shuffle의 여부까지 정해서 손쉽게 데이터셋을 나눌수 있다.

이때 random_state 값은 호출할 때마다 같은 학습/테스트 용 데이터 세트를 생성하기위해 특정 숫자를 지정을 해두는 것이다. 개인적으로 숫자를 고정으로 정해놓고 쓰는것이 개인적인 경험으로는 좋다고 생각한다.
Estimator 이해 및 fit(), predict() 매서드
사이킷런에서는 분류 알고리즘을 구현한 클래스를 Classifier로, 그리고 회귀 알고리즘을 구현한 클래스를 Regressor로 지칭한다. 이둘을 합쳐서 Estimator 클래스라고 부른다. 즉, 지도학습의 모든 알고리즘을 구현한 클래스를 통칭해서 Estimator라고 부른다. 당연히 Estimator 클래스느fit()과 predict()를 내부에서 구현하고 있다.
cross_val_score()와 같은 evaluation 함수, GridSearchCV와 같은 하이퍼 파라미터 튜닝을 지원하는 클래스의 경우 이 Estimator를 인자로 받는다. 인자로 받은 Estimator에 대해서 cross_val_score(), GridSearchCV.fit() 함수 내에서 이 Estimator의 fit()과 predict()를 호출해서 평가를 하거나 하이퍼 파라미터 튜닝을 하는 것이다.
사이킷런에서 비지도학습인 차원 축소, 클러스터링, 피처 추출 등을 구현한 클래스 역시 대부분 fit()과 transform()을 적용한다. 비지도학습과 피처 추출에서 fit()은 학습의 fit()이 아닌 입력 데이터의 형태에 맞춰 데이터를 변환하기 위한 사전 구조를 맞추는 메서드다. fit()으로 변환을 위한 사전 구조를 맞추면 이후 입력 데이터의 차원 변환, 클러스터링, 피처 추출 등의 실제 작업은 transform()으로 수행한다.
교차 검증
앞에서 알고리즘을 학습시키는 데이터와 이에 대한 예측 성능을 평가하기 위한 별도의 테스트용 데이터가 필요하다고 했었다. 하지만 단순하게 이것만 사용해서는 과적합의 문제를 해결을 못하는 경우가 다반사다. 여기서 과적합이란 모델이 학습 데이터에만 과도하게 최적화되어, 실제 예측을 다른 데이터로 수행할 경우에는 예측 성능이 과도하게 떨어지는 것을 의미한다. 고정된 학습 데이터와 테스트 데이터로 평가를 하다보면 테스트 데이터에만 과적합되는 학습모델이 만들어져 다른 테스트 데이터가 들어올 경우에 성능이 급 저하되는 상황이 발생한다. 이를 해결하기 위해서 교차 검증이라는 방법을 사용한다.
교차 검증은 데이터 편중을 막기 위해서 별도의 여러 세트로 구성된 학습 데이터 세트와 검증 데이터 세트에서 학습과 평가를 수행하는 것이다. 대부분의 ML모델의 성능 평가는 교차 검증 기반으로 1차 평가를 한 뒤에 최종적으로 테스트 데이터 세트에 적용해 평가하는 프로세스를 따른다. 전체 데이터 세트 = 학습용 데이터 세트(학습 데이터 세트 + 검증 데이터 세트 ) + 테스트용 데이터 세트
K 폴드 교차 검증
K 폴드 교차 검증은 가장 보편적으로 사용되는 교차 검증 기법이다. 먼저 K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습과 검증 평가를 반복적으로 수행하는 방법이다.
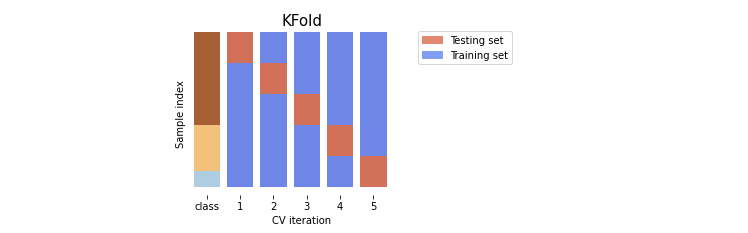
Stratified K 폴드
Stratified K 폴드는 불균형한 분포도를 가진 레이블 데이터 집합을 위한 K폴드 방식이다. 불균형한 분포도를 가진 레이블 데이터 집합은 특정 레이블 값이 특이하게 많거나 적어서 값의 분포가 한쪽으로 치우치는 것을 의미한다.
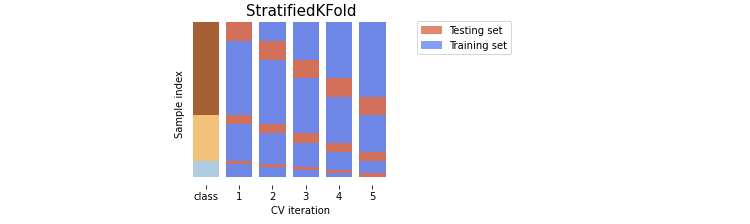
Stratified K 폴드의 경우 원본 데이터의 레이블 분포도 특성을 반영한 학습 및 검증 데이터 세트를 만들 수 있으므로 왜곡된 레이블 데이터 세트에서는 반드시 Stratified K 폴드를 이용해 교차 검증해야 한다. 일반적으로 Classification에서의 교차 검증은 K폴드가 아닌 Stratified K 폴드로 분할돼야 한다. Regression에서는 Stratified K 폴드가 지원되지 않는다. 회귀의 결정가뵤은 이산값 형태의 레이블이 아니라 연속된 숫자값이기 때문에 결정값별로 분포를 정하는 의미가 없기 때문이다.
Cross_val_score() - 교차 검증을 간편하게
cross_val_score(estimator, X, y=none, scoreing=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
핵심 파라미터
estimator: Classifier 또는 Regressor
X: 피처 데이터 세트
y: 레이블 데이터 세트
scoring: 예측 성능 평가 지표
cv: 교차 검증 폴드 수를 의미
cross_val_score() 수행 후 반환 값은 scoring 파라미터로 지정된 송능 지표 측정값을 배열 형태로 반환한다.

GridSearchCV - 교차 검증과 최적 하이퍼 파라미터 튜닝을 한 번에
교차 검증 기반으로 하이퍼 파라미터의 최적 값을 찾게 해준다. 즉 데이터 세트를 cross_validation을 위한 학습/테스트 세트로 자동으로 분할한 뒤에 하이퍼 파라미터 그리드에 기술된 모든 파라미터를 순차적으로 적용해 최적의 파라미터를 찾을 수 있게 해준다. 그러나 이 방법은 상대적으로 시간소요가 많이 발생을 한다.
그리드서치의 생성자로 들어가는 주요 파라미터
estimator: classifier, regressor,pipeline
param_grid: key+ 리스트 값을 가지는 딕셔너리가 주어진다
scoring: 예측 성능을 측정할 평가 방법을 지정
cv: 교차 검증을 위해 분할되는 학습/테스트 세트의 개수를 지정
refit: 디폴트가 True이며 True로 생성 시 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 estimator 객체를 해당 하이퍼 파라미터로 학습
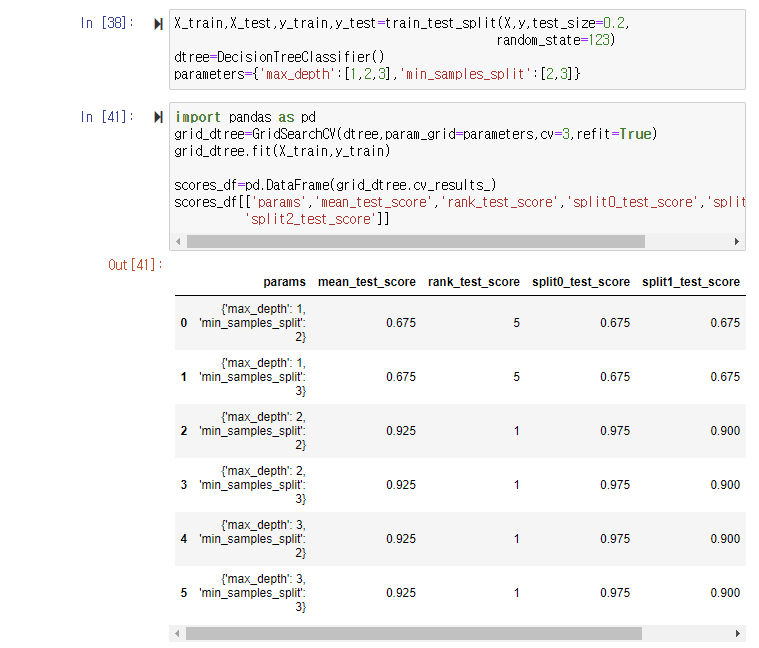
GridSearchCV 객체의 fit()을 수행하면 최고 성능을 나타낸 하이퍼 파라미터의 값과 그떄의 평가 결과 값이 각각 best_params_, best_score_ 속성에 기록이 된다. 이 속성을 이용해 최적 하이퍼 파라미터의 값과 그때의 정확도를 보면

데이터 전처리
데이터 전처리는 ML 알고리즘만큼 중요하다. ML 알고리즘 데이터에 기반하고 있기 때문에 어떤 데이터를 입력으로 가지느냐에 따라 결과도 크게 달라질 수 있다.
데이터 인코딩
머신러닝을 위한 대표적인 인코딩 방식은 레이블 인코딩과 원-핫 인코딩이 있다. 먼저 레이블 인코딩이란 카테고리 피처를 코드형 숫자 값으로 변환하는 것이다. 예를 들어 상품 데이터 구분이 TV, 냉장고, 컴퓨터... 로 돼있다면 TV:1, 냉장고:2, 컴퓨터:3과 같은 숫자형 값으로 변환하는 것이다.
레이블 인코딩
사이킷런의 레이블 인코딩은 LabelEncoder클래스로 구현한다. LabelEncoder를 객체로 생성한 후 fit()과 transform()을 호출해 레이블 인코딩을 수행한다.

레이블 인코딩은 간단하게 문자열 값을 숫자형 카테고리 값으로 변환한다. 하지만 레이블 인코딩이 일괄적인 숫자 값으로 변환이 되면서 몇몇 ML알고리즘에는 이를 적용할 경우 예측 성능이 떨어지는 경우가 발생할 수 있음. 이는 숫자 값의 크고 작음에 대한 특성이 작용하기 때문이다. 따라서 레이블 인코딩은 선형회귀와 같은 ML알고리즘에는 적용하지 않아야한다. 트리 계열의 ML알고리즘은 숫자의 이러한 특성을 반영하지 않음으로 상관이 없다.
원-핫 인코딩 (One-Hot Encoding)
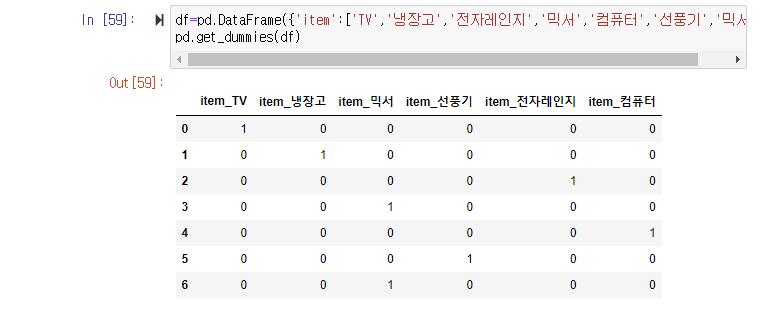
원-핫 인코딩은 피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방식이다. 원-핫 인코딩 역시 사이킷런에서 OneHotEncoder 클래스로 쉽게 변환이 가능하다. 단, LabelEncoder와 다르게 약간 주의할 점이 있다.
1. OneHotEncoder로 변환하기 전에 모든 문자열 값이 숫자형으로 변환되어야 함
2. 입력 값으로 2차원 데이터가 필요함

위 방법과 같이 one-hot encoding을 하면 번거로운 감이 있다 get_dummies()를 사용면 one-hot encoding을 좀 더 쉽게 이용할 수 있다.
피처 스케일링과 정규화
서로 다른 변수의 값 볌위를 일정한 수준으로 맞추는 작업을 피처 스케일링이라고 한다. 대표적인 방법으로 표준화(Standardization)와 정규화(Normalization)이 있다.
StandardScaler
StandardScaler는 표준화를 쉽게 지원하기 위한 클래스이다. 즉, 개별 피처를 평균이 0이고, 분산이 1인 값으로 변환해준다. 이렇게 가우시안 정규 분포를 가질 수 있도록 데이터를 변환하는 것은 몇몇 알고리즘에서 매우 중요하다. 특히 사이킷런에서 구현한 RBF 커널을 이용하는 서포트 벡터 머신이나 선형회귀, 로지스틱 회귀는 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현됐기 때문에 사전에 표준화를 적용하는 것은 예측 성능 향상에 중요한 요소가 될 수 있다.

MinMaxScaler
MinMaxScaler는 데이터값을 0과 1 사이의 범위 값으로 변환한다. 데이터의 분포가 가우시안 분포가 아닐 경우에 Min, Max Scale을 적용해 볼 수 있다.
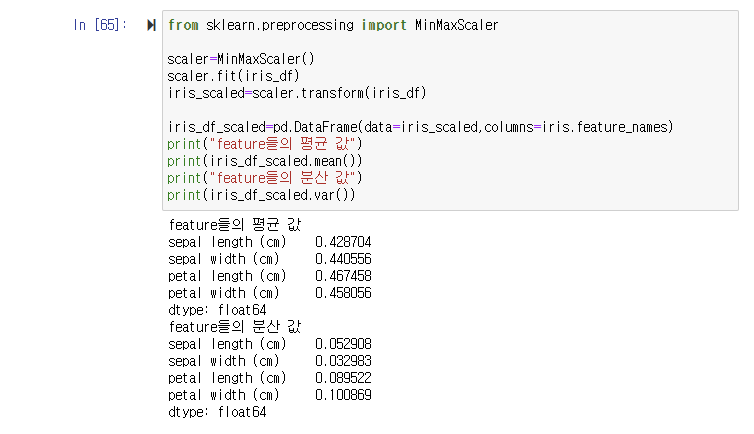
학습 데이터와 테스트 데이터 스케일링 변환 시 유의점
Scaler 객체를 이용해 학습 데이터 세트로 fit()와 transform()을 적용하면 테스트 데이터 세트로는 다시 fit()을 수행하지 않고 학습 데이터 세트로 fit()을 수행한 결과를 이용해 transform()변환을 테스트 데이터 세트에도 적용해야한다. 즉, 학습 데이터 세트로 fit()을 수행한 결고를 이용해 transform()변환을 테스트 데이터 세트에도 적용해야한다.
Tip
1. 가능하다면 전체 데이터의 스케일링 변환을 적용한 뒤 학습과 테스트 데이터로 분리
2. 1이 여의치 않다면 테스트 데이터 변환 시에는 fit()이나 fit_transform()을 적용하지 않고 학습 데이터로 이미 fit()된 Scaler 객체를 이용해 transform()으로 변환
'Machine Learning' 카테고리의 다른 글
| [파이썬 머신러닝 완벽가이드(위키북스)] : 분류 part1 (0) | 2021.11.19 |
|---|---|
| [파이썬 머신러닝 완벽가이드(위키북스)] : 평가 (0) | 2021.11.11 |
| [파이썬 머신러닝 완벽가이드(위키북스)] : 데이터 핸들링 part2 - Pandas (0) | 2021.11.03 |
| [파이썬 머신러닝 완벽가이드(위키북스)] : 데이터 핸들링 part1 - Pandas (0) | 2021.11.01 |
| [파이썬 머신러닝 완벽가이드(위키북스)] : Numpy (0) | 2021.11.01 |




댓글