회귀
회귀 분석은 데이터 값이 평균과 같은 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법이다. 회귀는 회귀 계수의 선형/비선형 여부, 독립변수의 개수, 종속변수의 개수에 따라 여러 가지 유형으로 나눌 수 있다. 회귀에서 가장 중요한 것은 바로 회귀 계수이다. 이 회귀 계수가 선형이냐 아니냐에 따라 선형, 비선형 회귀로 나눌 수 있다. 그리고 독립변수의 개수가 한 개인지 여러 개인지에 따라 단일 회귀, 다중 회귀로 나뉜다.
여러 가지 회귀 중에서 선형 회귀가 가장 많이 사용된다. 선형 회귀는 실제 값과 예측가뵤의 차이를 최소화하는 직선형 회귀선을 최적화하는 방식이다. 선형 회귀 모델은 규제 방법에 따라 다시 별도의 유형으로 나뉠 수 있다. 규제는 일반적인 선형 회귀의 과적합 문제를 해결하기 위해서 회귀 계수에 페널티 값을 적용하는 것을 말한다. 대표적인 선형회귀모델은 아래와 같다.
일반 선형 회귀 : 예측값과 실제 값의 RSS(Residual Sum of Squares)를 최소화 할 수 있도록 회귀 계수를 최적화하며, 규제를 적용하지 않은 모델이다.
릿지 : 릿지 회귀는 선형 회귀에 L2 규제를 추가한 회귀 모델이다. 릿지 회귀는 L2 규제를 적용하는데, L2 규제는 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키기 위해서 회귀 계수 값을 더 작게 만드는 규제 모델이다.
라쏘 : 라쏘 회귀는 선형 회귀에 L1 규제를 적용한 방식이다. L2 규제가 회귀 계수 값의 크기를 줄이는 데 반해, L1 규제는 예측 영향력이 작은 피처의 회귀 계수를 0으로 만들어 회귀 예측 시 피처가 선택되지 않게 하는 것이다. 이러한 특성 때문에 L1규제는 피처 선택 기능으로도 불림
엘라스틱넷 : L2, L1 규제를 함께 결합한 모델이다. 주로 피처가 많은 데이터 세트에 적용되며, L1 규제로 피처의 개수를 줄임과 동시에 L2규제로 계수 값의 크기를 조정한다.
로지스틱 회귀 : 로지스틱 회귀는 회귀라는 이름이 붙어 있지만, 사실은 분류에 사용되는 선형 모델이다. 로지스틱 회귀는 매우 강력한 분류 알고리즘이다. 일반적으로 이진 분류뿐만 아니라 희소 영역의 분류, 예를 들어 텍스트 분류와 같은 영역에서 뛰어난 예측 성능을 보인다.
단순 선형 회귀를 통한 이해
단순 선형 회귀는 독립변수도 하나, 종속변수도 하나인 선형 회귀이다. 예를 들어, 주택 가격이 주택의 크기로만 결정된다고 가정해보자 x축이 주택의 크기, Y축이 주택의 가격인 2차원 평면에서 특정 기울기와 절편을 가진 1차 함수 식으로 모델링할 수 있다. 실제 주택 가격은 이러한 1차 함숫값에서 실제 값만큼의 오류 값을 뺀 값이 된다. 이렇게 실제 값과 회귀 모델의 차이에 따른 오류 값을 남은 오류, 즉 잔차라고 부른다. 최적의 회귀 모델을 만든다는 것은 바로 전체 데이터의 잔차(오류 값) 합이 최소가 되는 모델을 만든다는 의미이다. 동시에 오류 값 합이 최소가 될 수 있는 최적의 회귀 계수를 찾는다는 의미도 된다
오류 값은 +,- 가 될 수 있다. 그래서 전체 데이터의 오류의 합을 구하기위해 절댓값을 취해서 더하거나(Mean Absolute Error), 오류 값의 제곱을 구해서 더하는 방식(RSS, Residual Sum of Square)을 취한다. 일반적으로 미분 등의 계산을 편리하게 하기 위해서 후자의 방법을 사용한다.
RSS는 회귀식의 독립변수 X, 종속변수 Y가 중심 변수가 아니라 w변수(회귀 계수)가 중심 변수임을 인지하는 것이 매우 중요하다. 회귀에서 이 RSS는 비용(Cost)이며 w변수로 구성되는 RSS를 비용 함수라고 한다. 머신러닝 회귀 알고리즘은 데이터를 계속 학습하면서 이 비용 함수가 반환하는 값(즉, 오류 값)을 지속해서 감소시키고 최종적으로는 더 이상 감소하지 않는 최소의 오류 값을 구하는 것이다.
경사 하강법(Gradient Descent)
W 파라미터의 개수가 적다면 고차원 방정식으로 비용 함수가 최소가 되는 W 변수값을 도출할 수 있지만, W 파라미터가 많으면 고차원 방정식을 동원하더라도 해결하기가 어렵다. 경사 하강법은 이러한 고차원 방정식에 대한 문제를 해결해 주면서 비용 함수 RSS를 최소화하는 방법을 직관적으로 제공하는 뛰어난 방식이다. -> 점진적으로 반복적인 계산을 통해 W 파라미터 값을 업데이트하면서 오류 값이 최소가 되는 W파라미터를 구하는 방식.
경사 하강법의 핵심은 "어떻게 하면 오류가 작아지는 방향으로 W값을 보정할 수 있을까?" 이다.

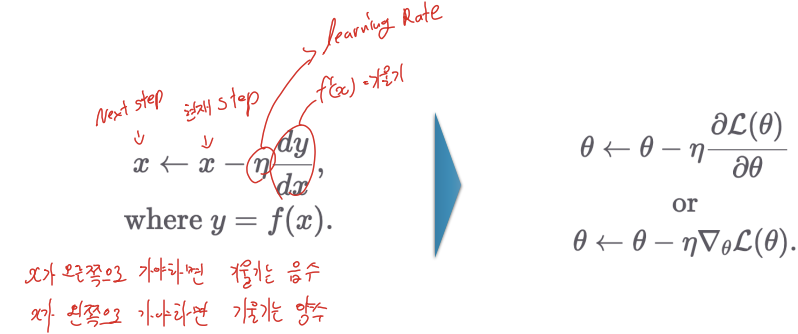
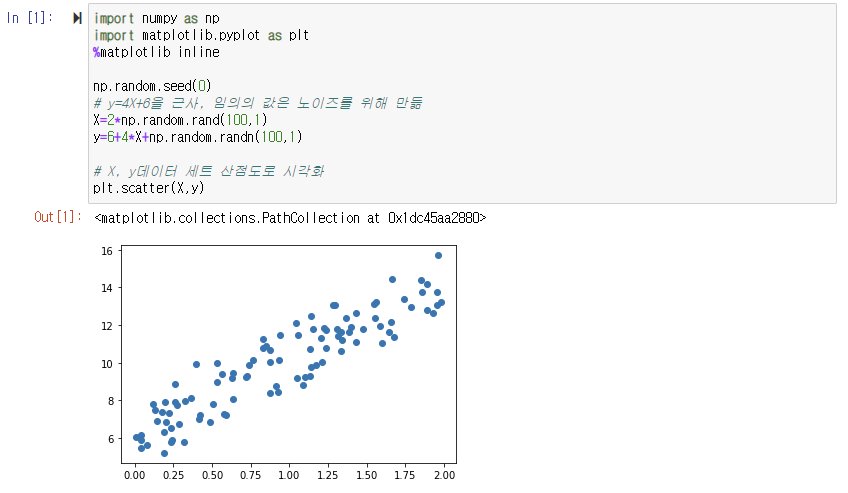
아래는 경사 하강법을 파이썬 코드로 구현을 해본 것이다. 간단한 회귀식인 y=4X+6을 근사하기 위한 100개의 데이터 세트를 만들고, 여기에 경사 하강법을 이용해 회귀 계수를 도출하는 것이다.
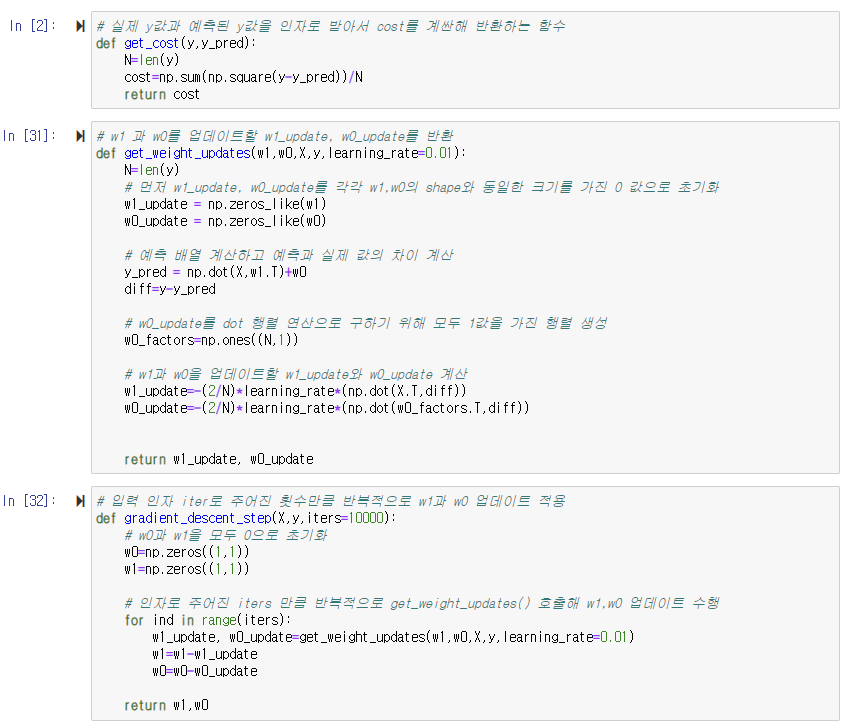
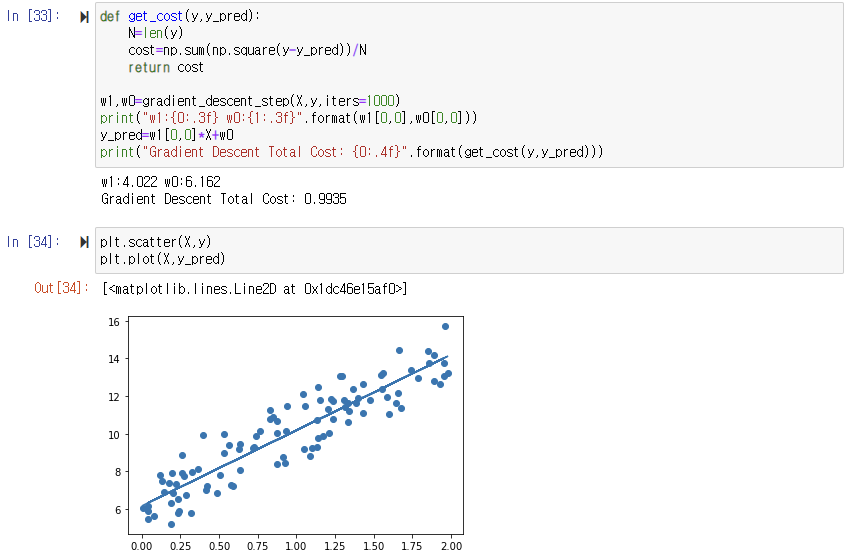
경사 하강법을 이용해 회귀선이 잘 만들어졌음을 알 수 있다. 일반적으로 경사 하강법은 모든 학습 데이터에 대해 반복적으로 비용 함수 최소화를 위한 값을 업데이트하기 때문에 수행 시간이 매우 오래 걸린다는 단점이 있다. 이 때문에 실전에서는 대부분 확률적 경사 하강법(Stochastic Gradient Descent)을 이용한다.
확률적 경사 하강법은 전체 입력 데이터로 w가 업데이트되는 값을 계산하는 것이 아니라 일부 데이터만 이용해 w가 업데이트되는 값을 계산하므로 경사 하강법에 비해서 빠른 속도를 보장한다. 따라서 대용량의 데이터의 경우 대부분 확률적 경사 하강법이나 미니 배치 확률적 경사 하강법을 이용해 최적 비용 함수를 도출한다.
사이킷런 LinearRegression을 이용한 보스턴 주택 가격 예측
회귀 평가 지표
MAE : Mean Absolute Error(MAE)이며 실제 값과 예측값의 차이를 절댓값으로 변환해 평균한 것이다.
MSE : Mean Squares Error(MSE)이며 실제 값과 예측값의 차이를 제곱해 평균한 것이다.
RMSE : MSE 값은 오류의 제곱을 구하므로 실제 오류 평균보다 더 커지는 특성이 있으므로 MSE에 루트를 씌운 것이 RMSE(Root Mean Squared Error)이다.
R^2 : 분산 기반으로 예측 성능을 평가한다. 실제 값의 분산 대비 예측값의 분산 비율을 지표로 하며, 1에 가까울수록 예측 정확도가 높다.
LinearRegression을 이용해 보스턴 주택 가격 회귀 구현

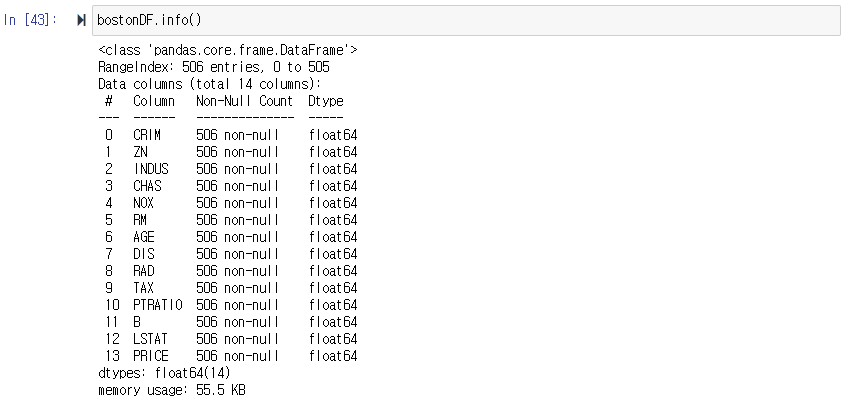
데이터 세트 피처의 NULL값은 없으며 모두 float형이다. 다음으로 각 칼럼이 회귀 결과에 미치는 영향이 어느 정도인지 시각화를 해보았다.
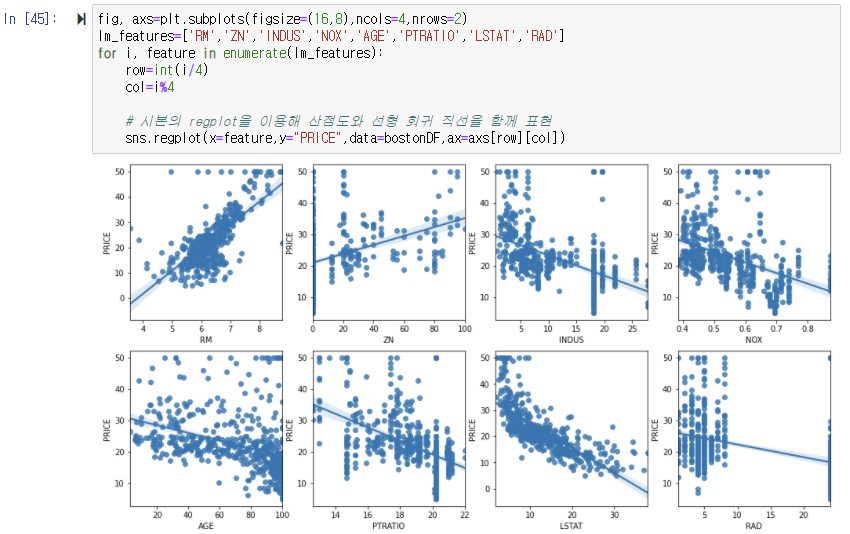
seabron의 regplot() API는 X, Y 축 값의 산점도와 함께 선형 회귀 직선을 그려준다. matplotlib subplot()을 이용해 각 ax마다 칼럼과 PRICE의 관계를 표현한다. matplotlib의 subplot()은 여러 개의 그래프를 한 번에 표현하기 위해 자주 사용된다. 인자로 입력되는 ncols는 열 방향으로 위치할 그래프의 개수이며, nrows는 행 방향으로 위치할 그래프의 개수이다. ncols=4, nrows=2이면 2개의 행과 4개의 열을 가친 총 8개의 그래프를 행, 열 방향으로 그릴 수 있다.
혹은 seaborn의 pairplot(DataFrame)을 사용하면 계수들끼리의 상관관계 또한 볼 수 있다. 한번에 타깃 값과 각 피처들의 값의 상관관계를 볼 수 있다.

LinearRegression 클래스를 이용해 보스턴 주택 가격의 회귀 모델을 만들어 보았다.

LinearRegression으로 생성한 주택 가격 모델의 intercept과 coefficients(회귀계수) 값을 보면, 절편은 LinearRegression 객체의 intercept_ 속성에, 회귀 계수를 coef_ 속성에 값이 저장돼있습니다.
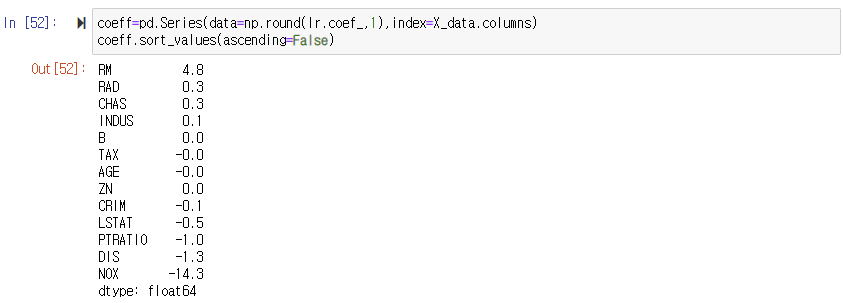
RM이 양의 값으로 회귀 계수가 가장 크며, NOX 피처의 회귀 계수 음의 값이 너무 큰 것을 알 수 있다.
다항 회귀와 과대 적합/과소 적합 이해
지금까지 설명한 회귀는 독립변수와 종속변수의 관계가 일차 방정식 형태로 표현된 회귀였다. 하지만 세상의 모든 관계를 직선으로만 표현할 수는 없다. 회귀가 독립변수의 단항식이 아닌 2차, 3차 방정식과 같은 다항식으로 표현되는 것을 다항(Ploynomial) 회귀라고 한다. 한 가지 주의할 것은 다항 회귀를 비선형 회귀로 혼동하기 쉽지만, 다항 회귀는 선형 회귀하는 점이다. 회귀에서 선형/비선형 회귀를 나누는 기준은 회귀 계수가 선형/비선형인지에 따른 것이지 독립변수의 선형/비선형 여부와는 무관하다.
사이킷런은 다항 회귀를 위한 클래스를 명시적으로 제공하지 않는다. 대신 다항 회귀 역시 선형 회귀이기 때문에 비선형 함수를 선형 모델에 적용시키는 방법을 사용해 구현해야한다. 이를 위해 사이킷런은 PlotnomialFeatures 클래스를 통해 피처를 Plotnomial(다항식) 피처로 변환한다. PlotnomialFeatures 클래스는 degree 파라미터를 통해 입력받은 단항식 피처를 degree 파라미터를 통해 입력 받은 단항식 피처를 degree에 해당하는 다항식 피처로 변환한다. 다른 전처리 변환 클래스와 마찬가지로 PlotnimialFeatures 클래스는 fit(), transform() 메서드를 통해 이 같은 변환 작업을 수행한다. 아래 코드는 PloynomialFeatures를 이용해 단항 값[x1, x2]을 2차 다항 값으로 [1, x1, x2, x1^2, x1, x2, x2^2]로 변환하는 예제이다.

다항 회귀를 이용한 과소 적합 및 과적합 이해
다항 회귀는 피처의 직선적 관계가 아닌 복잡한 다항 관계를 모델링할 수 있다. 다항식의 차수가 높아질수록 매우 복잡한 피처 간의 관계까지 모델링이 가능하다. 하지만 다항 회귀의 차수(degree)를 높일수록 학습 데이터에만 너무 맞춘 학습이 이뤄져서 정작 테스트 데이터 환경에서는 정확도가 떨어진다. -> 과적합
또한 실제 데이터의 차원보다 너무 작게 다항식의 차수를 잡으면 모델이 학습을 너무 적게 해서 제대로 예측조차 못 할 수 있다. -> 과소 적합
편향-분산 트레이드오프(Bias-avarieance Trade off)
편향-분산 트레이드오프는 머신러닝이 극복해야 할 가장 중요한 이슈 중에 하나이다.

위 그림의 '양궁 과녁' 그래프는 편향과 분산의 고/저의 의미를 직관적으로 잘 표현하고 있다. 위 그림 상단의 왼쪽의 저편향/저분산은 예측 결과가 실제 결과와 매우 근접하는 것뿐만 아니라 예측 변동이 크지 않고 특정 부분에 집중돼 있는 아주 뛰어난 성능을 보여주는 모습이다. 상단 오른쪽에 저편향/고분산은 예측 결과와 실제 결과와 근접하지만 예측 변동이 있는 것을 알 수 있다. 하단 왼쪽의 고편향/저분산은 정확한 예측을 못하면서 예측 결과가 특정 부분에 분포해 있는 모습이다. 마지막으로 하단의 오른쪽의 고편향/고분산은 정확한 예측 결과를 벗어나면서도 예측 변동도 큰것으로 볼 수 있다.
일반적으로 편향과 분산은 한 쪽이 높으면 한 쪽이 낮아지는 경향이 있다. 즉, 편향이 높으면 분산은 낮아지고(과소적합) 반대로 분산이 높으면 편향이 낮아진다(과적합). 따라서 우리는 편향을 낮추고 분산을 높이면서 전체 오류가 가장 낮아지는 '스윗스팟'을 찾아야한다.
'Machine Learning' 카테고리의 다른 글
| [파이썬 머신러닝 완벽가이드(위키북스)] : Regression 회귀 part3 로지스틱, 회귀 트리 (0) | 2021.11.25 |
|---|---|
| [파이썬 머신러닝 완벽가이드(위키북스)] : Regression 회귀 part2 규제 선형 모델 - 릿지, 라쏘, 엘라스틱넷 (0) | 2021.11.25 |
| [파이썬 머신러닝 완벽가이드(위키북스)] : 분류 part5 스태킹 앙상블 (0) | 2021.11.21 |
| [파이썬 머신러닝 완벽가이드(위키북스)] : 분류 part4 캐글 신용카드 사기 검출 실습 (0) | 2021.11.21 |
| [파이썬 머신러닝 완벽가이드(위키북스)] : 분류 part3 (GBM, XGBoost, LightGBM) (0) | 2021.11.21 |




댓글